相信站长朋友们在搭建网站的时候多数是选择本地电脑搭建网站环境并测试,但也有一些站长比如说草根seo博客小编则喜欢在测试网站模板的时候使用云服务器搭建网站并测试。但在服务器上测试网站各种数据 的时候网页都是不完美的,所以不想让搜索引擎收录,所以会在robots.txt文件中禁止所有搜索引擎蜘蛛爬行,而等到网站真正上线的时候又忘记把robots.txt文件改回正常默认的允许所有搜索引擎蜘蛛爬行,从而导致网站收录异常。今天我们就来说说robots.txt的写法以及robots.txt存在限制指令如何解决,一起来学习:
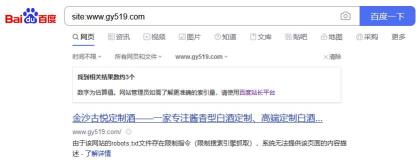
出现robots.txt文件存在限制指令的快照,是因为网站上线前或者测试的时候,网站因为要更新自适应模板,要不断的测试内容、标题调用等需要不断的修改,小编为了不让搜索引擎抓取,所以在robots.txt文件屏蔽了所有搜索引擎的收录,robots.txt代码如下:
User-agent: *Disallow: /那么robots.txt存在限制指令怎么办呢?
第一步,打到robots.txt文件,把原来的代码改成允许所有搜索引擎访问,(又或者复制原来网站程序自带的robots.txt 覆盖网站上的文件)代码如下 :
User-agent: *Allow: /第二步,改好了robots.txt后,再百度的站长资源平台上更新robots文件, 这时候等百度快照更新过来之后就可以了。
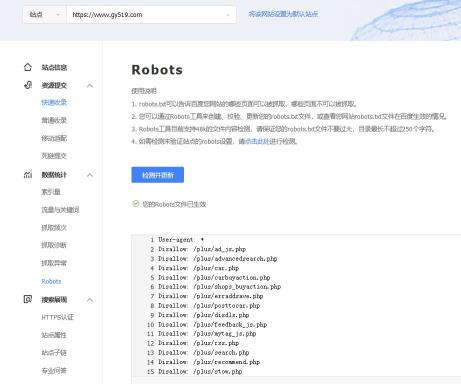
现在我们来看看robots文件写法:
文件写法
User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符
Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录
Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录
Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以”.htm”为后缀的URL(包含子目录)。
Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。
Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录
Allow: /tmp 这里定义是允许爬寻tmp的整个目录
Allow: .htm$ 仅允许访问以”.htm”为后缀的URL。
Allow: .gif$ 允许抓取网页和gif格式图片
Sitemap: 网站地图 告诉爬虫这个页面是网站地图
文件用法
例1. 禁止所有搜索引擎访问网站的任何部分
User-agent: *Disallow: /实例分析:淘宝网的 Robots.txt文件
User-agent: BaiduspiderDisallow: /User-agent: baiduspiderDisallow: /很显然淘宝不允许百度的机器人访问其网站下其所有的目录。
例2. 允许所有的robot访问 (或者也可以建一个空文件 “/robots.txt” file)
User-agent: *Allow: /例3. 禁止某个搜索引擎的访问
User-agent: BadBotDisallow: /例4. 允许某个搜索引擎的访问
User-agent: Baiduspiderallow:/例5.一个简单例子
在这个例子中,该网站有三个目录对搜索引擎的访问做了限制,即搜索引擎不会访问这三个目录。
需要注意的是对每一个目录必须分开声明,而不要写成 “Disallow: /cgi-bin/ /tmp/”。
User-agent:后的*具有特殊的含义,代表“any robot”,所以在该文件中不能有“Disallow: /tmp/*” or “Disallow:*.gif”这样的记录出现。
User-agent: *Disallow: /cgi-bin/Disallow: /tmp/Disallow: /~joe/好了,关于robots.txt文件的使用方法我们就介绍到这里了,希望大家在测试搭建网站的时候要注意robots.txt是不是改过,要是改过等网站上线的时候要改回默认或者允许搜索引擎访问,否则可能导致网站不收录。