几乎每个搜索词都是一个隐含的或明确的问题,借助语音搜索和移动设备,Google能够识别搜索查询以及用户意图或背后的意义就显得尤为重要,这有助于搜索引擎为用户提供精确的搜索结果。
2009年,谷歌搜索质量团队技术负责人Ori Allon在接受IDG采访时表示:“我们在搜索质量方面非常努力,以更好地理解查询的上下文以及查询的内容,查询不是所有术语的总和,查询具有背后的意义。对于像“Britney Spears”和“Barack Hussein Obama Jr”这样的简单查询,我们很容易对网页进行排名,但是当询问是’ What medicine should I take after my eye surgery ‘,那就更困难了,我们需要了解这个意思……“最终,谷歌希望识别用户或搜索意图。
Google如何识别搜索意图
为此,Google必须了解上下文,在讨论上下文时,我们必须区分搜索查询上下文,如术语之间的关系,用户上下文(如位置和(搜索)历史)以及主题上下文,一些形式的背景是动态的,并且可以随着时间而改变。通过考虑所有可用的上下文形式,可以为每个搜索查询推断个人对用户意图的深刻理解。
Google因此必须回答以下问题:
用户在哪里?
用户使用哪种设备进行搜索?
用户过去对什么感兴趣?
如何使用的术语相互关联?
搜索请求中包含哪些实体?
在哪些主题上下文中使用了这些术语?
Google可以使用客户信息,GPS数据和IP地址快速回答前两个问题。第三个问题可以通过搜索历史记录,SERP中的点击和一般在线行为来解答。
在过去的三个问题,其中涉及到的搜索查询的实际意义,不能那么容易回答。
输入RankBrain
Google推出的RankBrain是改善扩展性和性能的一大步,为了让Google能够识别搜索词的含义,必须使用统计方法模仿一种语义理解。这需要使用评论或注释对搜索术语进行分类以及相关主题尚不知晓的术语映射,由于每天都会向Google输入大量搜索词,因此无法手动进行,为了实现可扩展性,它必须使用聚类分析和自动聚类进行。
自2015年以来,谷歌已经能够做到这一点,当时它以RankBrain的形式推出了机器学习,这帮助Google加入了可扩展性和重构的搜索查询语义理解之间的点。
解释搜索查询的方法
Google使用所谓的矢量空间分析来解释搜索查询,这些将搜索查询转换为向量,并将这些关系绘制到向量空间中的其他项,通过比较关系模式,即使特定搜索查询先前未被分析,也可以识别搜索意图或意义。
在这方面,像个人搜索结果上的点击率这样的用户信号似乎扮演着特别重要的角色,在Google员工参与的两个科学项目中,我发现了有关如何解决此问题的算法的有趣信息。
在通过属性参数化学习个人搜索中的用户交互时,解释了Google如何能够使用对用户行为和单个文档的分析来创建搜索查询与点击文档之间的语义属性关系 – 甚至支持自我学习排名算法:
在本文档中,Google提供了两种方法来为搜索查询建立内容。所谓的“提升分数”在第一个题为“词语共现集群”中起着核心作用:
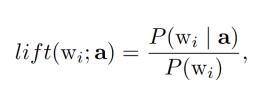
在这个公式中,“wi”代表与单词根相关的所有术语,如拼写错误,复数,单数和同义词。“a”可以是任何用户交互,例如搜索特定搜索项或访问特定页面。如果举升得分例如是5,那么正在搜索“wi”的概率比搜索“wi”的一般可能性高5倍。
“大型电梯得分有助于我们围绕有意义的单词构建话题,而不是无趣的单词。在实践中,可以在最近的时间窗口内使用Google搜索历史中的词频来估计概率。“
这使得可以将术语分配给诸如“梅赛德斯”之类的特定实体和/或 – 如果存在对替换汽车零件的搜索 – 将其分配给主题上下文集群“汽车”。然后,上下文集群或实体也可以分配给它的词语这通常表现为与搜索词共现。这使得为特定主题快速创建搜索词wordcloud成为可能。提升分数的大小决定了与该主题的接近程度:
“我们使用提升分数来按重要性对单词进行排序,然后对其进行阈值以获得一组与单词高度相关的单词。”
当“wi”已知时,这种方法特别有用,例如搜索已知的品牌或类别。如果无法明确定义“wi”,因为同一主题的搜索条件太多,Google可以使用第二种方法:加权bigraph聚类。
该方法基于两个假设:
具有相同意图短语的用户搜索查询的方式不同。搜索引擎仍显示相同的搜索结果。
对于任何给定的搜索查询,在顶部搜索结果中显示类似的URL。
应用这种方法,将搜索词与顶级网址进行比较,并创建查询网址对,其关系也根据用户的点击率和网页展示进行加权。这使得识别不包含相同词汇根的搜索词之间的相似性成为可能,从而创建语义聚类。
实体在解释搜索查询中的作用
谷歌希望找出问题所指的实体是什么。通过查看搜索词中的实体以及实体之间的关系上下文,Google可以识别所查找的实体。
即使结果确实有所不同,Google也认识到即使搜索查询中未显示名称,也会搜索“Bill Bowerman”和“Phil Knight”实体。我是否问了一个隐含的问题,如“创始人耐克”还是一个明确的问题,都没有区别。实体“耐克”和关系背景“创始人”就足够了。
此功能常常被错误地归因于RankBrain和/或Google的机器学习技术。然而,它实际上起源于Hummingbird 的功能,与知识图谱一起。Ergo:在RankBrain出现之前,Google能够做到这一点。
早在2009年,谷歌就推出了第一批用于解释搜索条件的语义技术,其“相关搜索”。该技术的发明者Ori Allon已经为谷歌的用户准备了对排名影响更大的底层技术。Allon开发的技术专利可以在这里找到。
该专利主要处理搜索查询的解释和微调。这意味着RankBrain稍后可能会利用其机器学习技术进行构建。自从RankBrain(如果不是更早)以来,Google就能够使用机器学习对搜索查询进行可扩展的语义解释。
根据该专利,搜索查询的微调涉及经常在原始搜索查询或同义词的排名文件中一起出现的特定实体。
RankBrain之前的问题是在查找实体并将其存储在知识图中时缺乏可伸缩性。知识图主要基于来自维基数据的信息,维基数据由维基百科实体验证 – 这意味着它是手动策划的,因此是静态和不可扩展的系统。
“维基百科通常被用作实体制图系统的基准。如第3.5小节所述,这会产生足够好的结果,而且我们认为,如果在这方面进一步努力会导致合理的收益,那将是令人惊讶的。“
资料来源:从Freebase到Wikidata – Great Migration
Google变好(还是很棒?)
可以有把握地认为,谷歌一直致力于开发包含语义影响的搜索引擎,以便至少从2007年起更好地理解搜索查询和文档的含义。
到目前为止,在知识图和机器学习等语义结构方面,谷歌似乎非常接近前副总裁玛丽莎梅表示的目标,即从纯粹基于关键词的搜索引擎转向概念或背景基于搜索引擎。
“现在,谷歌对关键词非常好,这是我们认为搜索引擎应该能够随着时间克服的局限性。人们应该能够提出问题,我们应该理解他们的意思,或者他们应该能够在概念层面上谈论事情。我们看到很多基于概念的问题 – 而不是在页面上显示哪些词,但更像是“这是怎么回事?”。“
而且,实际上,Google实现这一目标的时机已经到了 – 如果您认为Voice Search正在全球进军,搜索查询变得越来越复杂。