几乎每个人都听过“机器学习”这个词,但大多数人并不完全明白他们的意思,机器学习不是简单地应用于问题的单一公式。有许多算法可供选择,每种算法都可用于实现不同的目标。这是一系列文章中的第一篇,它将介绍机器学习算法,以帮助您了解它们的工作方式以及何时使用每种算法。
什么是机器学习?
在我们进一步讨论之前,让我们确切地定义我们正在谈论的内容。什么是机器学习?机器学习是关于构建具有自适应参数的程序,这些参数可根据程序接收的数据自动调整。通过适应以前看到的数据,程序能够改善他们的行为。它们还可以推广数据,这意味着程序可以对以前看不到的数据集执行功能。
如果这个定义让你联想到人工智能,那么你就走在了正确的轨道上:机器学习实际上是人工智能的一个子领域,机器学习算法可以被认为是帮助计算机学习更智能操作的构建块。
机器学习算法有两种类型:监督和非监督。监督算法使用输入向量和目标向量(或预期输出)作为训练数据,而无监督算法仅使用输入向量,无监督算法使用称为聚类的过程来识别目标向量,这涉及在数据中创建组和子组。
例如,假设您正在教孩子识别不同类型的蔬菜,监督学习将涉及向孩子提供蔬菜并说:“这是胡萝卜,这些是豌豆,这是西兰花。“无监督的学习将涉及在没有给出他们的名字的情况下展示蔬菜,并让孩子对蔬菜进行分类:胡萝卜是橙色的,豌豆和西兰花是绿色的。然后,孩子将创建一个子类别来区分绿色蔬菜。豌豆是绿色和小的,西兰花是绿色和大。
参考:机器学习的亮点和挑战
了解决策树
我要介绍的第一个算法是决策树,这是一种较旧的算法,目前尚未广泛使用,但它仍然是学习我们将提出的更高级算法的基础。
决策树是监督预测模型,它可以通过根据收到的输入值回答问题来学习预测离散或连续输出。
让我们看一个使用现实世界数据集的例子:1986-1987的美国职业棒球大联盟(MLB)球员数据,我们将根据他在主要联赛中的比赛年数以及他上一年的点击次数来确定职业球员的薪水。
下图说明了我们的培训数据,彩色圆点表示单个玩家的工资:蓝色/绿色圆点代表低工资,红色/黄色代表高工资。
决策树使用不同的属性来重复地将数据拆分成子集,直到子集是纯的,这意味着它们都共享相同的目标值。在这种情况下,我们将空间划分为区域,并使用每个区域的平均工资作为未来玩家的预测工资,目标是最大化区域内的相似性,同时最小化区域之间的相似性。
计算机创建了以下区域:
R1 -小于五年经验/平均$ 166,000的薪水
R2 -five年以上经验/小于118次点击/平均403000 $工资
R3 -five年以上经验/ 118次点击以上/平均$ 846,000的薪水
然后使用这些区域对样本外数据进行预测,注意:只有三个预测,这是等效的回归树:
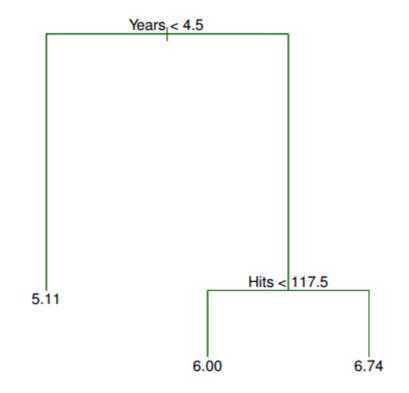
第一次拆分是年份<4.5,因此它位于树的顶部。如果拆分规则为true,请按左分支,如果为false,请按照右侧分支。左侧分支中玩家的平均工资为166,000美元,因此您使用该值标记它。(工资除以1,000并对数转换为5.11。)对于右分支中的玩家,命中数<117.5进一步分割,这进一步将球员划分为两个薪水区域:403,000美元(转换为6.00)和$ 846,000(转换为6.74)。
从这棵树,我们可以推断出以下内容:
美国职业棒球大联盟球员的比赛年数是决定他薪水的最重要因素,较低的薪水年数较少。对于年龄较低的美国职棒大联盟球员来说,命中率并不是决定薪水的重要因素。
对于已经参加更多年份的美国职业棒球大联盟球员来说,命中率是确定薪水的一个重要因素,更多的命中率与更高的薪水相对应。
量化子集的纯度
在决策树中,任何属性都可用于分割数据,但算法会根据结果子集的纯度选择属性和条件,子集的纯度由子集内的目标值的确定性确定。
为了测量子集的纯度,我们必须提供一个定量度量,以便决策树算法可以客观地选择要分割的最佳属性和条件。有多种方法可以测量一组值中的不确定性,但出于我们的目的,我们将使用熵(由H表示):
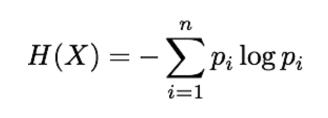
X – 得到的分裂 n – 子集
p i中不同目标值的数量 – 子集中第i 个目标值的比例
选择属性和条件后,您可以测量子集的杂质。为此,我们必须将所有子集的杂质聚合成一个度量。这是使用信息增益测量来完成的,该测量测量分裂后杂质的预期减少量。信息增益的公式如下:
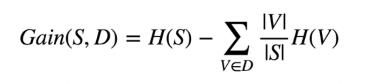
S – 分裂前的子集
D – 使用给定属性和条件
V 的分裂的可能结果- 假设所有值D可以逐个测量
V和S上的平行线表示该组的大小
更简单地说,增益计算分裂前后的熵差。
决策树有许多优点和缺点,在决定它们是否适合给定的用例时应予以考虑。
决策树的优点
可用于回归或分类
可以图形方式显示
高度可解释
可以指定为一系列规则
与其他ML算法相比,更接近人类决策
快速预测
功能不需要缩放
自动学习要素互动
倾向于忽略不相关的功能
如果特征和响应之间的关系是高度非线性的,那么非参数和其性能将优于线性模型
决策树的缺点
绩效通常不会与最好的监督学习方法竞争
可以轻松地过度训练训练数据,因此需要调整
数据的微小变化可能导致完全不同的树
递归二进制拆分使得“局部最优”决策可能不会导致全局最优树
高度不平衡的课程不适合
不适合使用非常小的数据集